Corpus Masoreticum. The Inculturation of Masora into Jewish Law and Lore from the 11th to the 14th Centuries. Digital Reconstruction of a Forgotten Intellectual Culture
Funded by the German Research Foundation
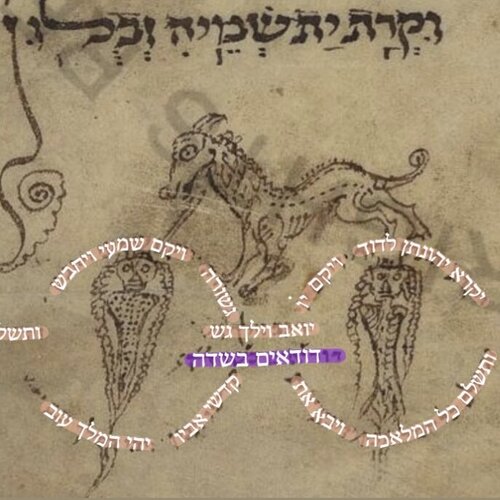
This project began in 2018 and is scheduled to run for 12 years. The aim is to conduct the first philological study of the Western European Masoretic tradition between the 11th and 14th centuries. In the first two funding phases, the richly decorated calligraphic Ashkenazic Bibles, the linear Masora and the micrographic Masora figurata illustrations in various manuscripts were examined philologically. The Masora figurata as well as significant parts of the linear Masora magna from nine medieval manuscripts have been transcribed and made available to the public in open access. So far, groundbreaking results have been achieved with regard to researching the philological quality of the Masora figurata as well as its exegetical and pedagogical function in various manuscripts.
As a digital project, Corpus Masoreticum is supported by a highly scalable digital cloud infrastructure that covers the entire workflow for the management of manuscript holdings, transcriptions, analyses and publications. Its centerpiece, the digital scholarly editing workspace BIMA 2.1, is based on three fundamental concepts: 1. IIIF-compatible manuscript repositories, 2. SVG-TextPath transcriptions, 3. a Neo4j graph database based on a loosely coupled text-as-a-graph data model. To date, BIMA 2. 1 hosts 112 manuscripts and displays over 7,000 (partially or fully transcribed) pages with almost 300,000 transcription lines, of which more than 500 pages have already been published under an Open Access Creative Commons CC-BY-SA 4.0 license:
Corpus Masoreticum & BIMA 2.1
The computational toolkits have been enhanced by the implementation of methods and algorithms such as machine text recognition (HTR) and correspondence analysis/seriation of lemma features.
Corpus Masoreticum runs its own publication series: Corpus Masoreticum Working Papers

, fol. 474r (transcribed). Masorah Rearranged: Eight Masoretic Lists in MS London Oriental 2091, fol. 335v corpus masoreticum working papers 6 (2023).")


.")



 Date 15 February 2024
Date 15 February 2024 Time 17:00 - 19:00 UTC+01:00
Time 17:00 - 19:00 UTC+01:00 Participation On-site
Participation On-site Language English
Language English Location Hannah Arendt Hall, S4 (HfJS Heidelberg)
Location Hannah Arendt Hall, S4 (HfJS Heidelberg)


![[Übersetzen nach: English]](/fileadmin/_processed_/0/5/csm_Vorlesungsverzeichnis_Sommersemester_2025_80206c7b4a.png "[Übersetzen nach: English]")