Corpus Masoreticum. The Inculturation of Masora into Jewish Law and Lore from the 11th to the 14th Centuries. Digital Reconstruction of a Forgotten Intellectual Culture
Förderung durch die Deutsche Forschungsgemeinschaft
Dieses Projekt begann 2018 und ist auf 12 Jahre Laufzeit angelegt. Ziel ist die erstmalige philologische Auseinandersetzung mit der westeuropäischen masoretischen Tradition zwischen dem 11. und 14. Jahrhundert. In den ersten beiden Förderphasen wurden vor allem die kalligraphisch reichhaltig verzierten aschkenasischen Bibeln, die lineare Masora wie die mikrographischen Masora figurata Illustrationen in verschiedenen Handschriften philologisch bearbeitet. Die Masora figurata sowie erhebliche Teile der linearen Masora magna von bislang neun mittelalterlichen Handschriften wurden transkribiert und der Öffentlichkeit im Open Access digital zugänglich gemacht. Bahnbrechende Ergebnisse hinsichtlich der Erforschung der philologischen Qualität der Masora figurata sowie ihrer exegetischen und pädagogischen Funktion in verschiedenen Handschriften konnten bislang erzielt werden.
Als digitales Projekt wird Corpus Masoreticum von einer hochskalierbaren digitalen Cloud-Infrastruktur unterstützt, die den gesamten Workflow für die Verwaltung von Manuskriptbeständen, Transkriptionen, Analysen und Publikationen abdeckt. Sein Herzstück, der digitale wissenschaftliche Editionsarbeitsbereich BIMA 2.1, basiert auf drei grundlegenden Konzepten: 1. IIIF-kompatible Manuskript-Repositorien, 2. SVG-TextPath-Transkriptionen, 3. eine Neo4j-Graph-Datenbank, die auf einem lose gekoppelten Text-as-a-Graph-Datenmodell basiert. Bis heute beherbergt BIMA 2.1 112 Manuskripte und zeigt über 7.000 (teilweise oder vollständig transkribierte) Seiten mit fast 300.000 Transkriptionszeilen an, von denen bereits mehr als 500 Seiten unter einer Open Access Creative Commons CC-BY-SA 4.0 Lizenz veröffentlicht wurden:
Corpus Masoreticum & BIMA 2.1
Die computergestützten Toolkits wurden durch die Implementierung von Methoden und Algorithmen wie der maschinellen Texterkennung (HTR) und der Korrespondenzanalyse/seriation von Lemmata-Features erweitert.
Corpus Masoreticum betreibt eine eigene Publikationsreihe: Corpus Masoreticum Working Papers

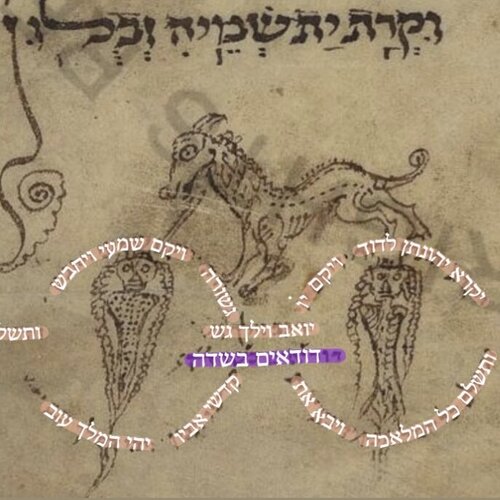
, fol. 474r (transcribed). Masorah Rearranged: Eight Masoretic Lists in MS London Oriental 2091, fol. 335v corpus masoreticum working papers 6 (2023).")


.")



 Datum 31. Januar 2024
Datum 31. Januar 2024 Uhrzeit 18:00 - 20:00 UTC+01:00
Uhrzeit 18:00 - 20:00 UTC+01:00 Teilnahme Hybrid
Teilnahme Hybrid Sprache Deutsch
Sprache Deutsch Ansprechperson Lehrstuhl für Bibel und Jüdische Bibelauslegung
Ansprechperson Lehrstuhl für Bibel und Jüdische Bibelauslegung Ort / Link Hannah-Arendt-Saal, S4 (HfJS Heidelberg)
Ort / Link Hannah-Arendt-Saal, S4 (HfJS Heidelberg)